A Fun Dive into Data Collection Adventures with Airflow and Playwright
Halifax’s housing crisis and the data project
Apartment rental data in Halifax is not widely available. A common practice is to use Condo sales data to do a conversion by a certain property sale and rent ratio. As this project is about data automation, it is inevitable to use web scraping to collect data from several major regional rental websites and property management companies’ websites.
As you may or may not know, Halifax, NS, Canada is experiencing a housing crisis for some time now. ‘It’s brutal’: Halifax housing program can’t meet demand as more face homelessness | Globalnews.ca.
This project aims is to build a data pipeline to collect rental market data in Halifax Region of Municipality ( HRM ) and provide some data analysis and visualisation. After some research, collecting data through several rental websites which display vacant rooms with rental prices and other information in the region could be an option. Well a better option is to purchase data api from some data research companies, and it also makes more sense to use property sales data to do a conversion. But having an automated live data feed is certainly valuable in the long run. By the end, I hope this could be a useful to have a better understanding of the local rental market for both renters and developers.
In this blog, I will be focusing on the data collection part.
Web scraping here is done using Playwright, an auto-testing tool to fetch the data. Although reverse engineering of Javascript code aiming at the backend on such websites is more suitable for large scale scraping, it requires considerable time and effort to do so. Given that HRM is a relatively small property rental market, on average only about hundreds apartment units are on display, and the data sources are scattered in small numbers among various websites, it makes sense to use Playwright to take advantage of the rapid development and make concessions on scraping speed.
Playwright has native support for async operations. Its browser management seems to be more intuitive than selenium. Playwright supports Javascript and Python and provides detailed examples in its documentation.
Web Scraping Workflow
It is better to use purchased proxies, but there are free options online like [free-proxy-list.net] and [proxyscrape.com] provide some free to use proxy IPs.
A basic flowchart to show the data pipeline.
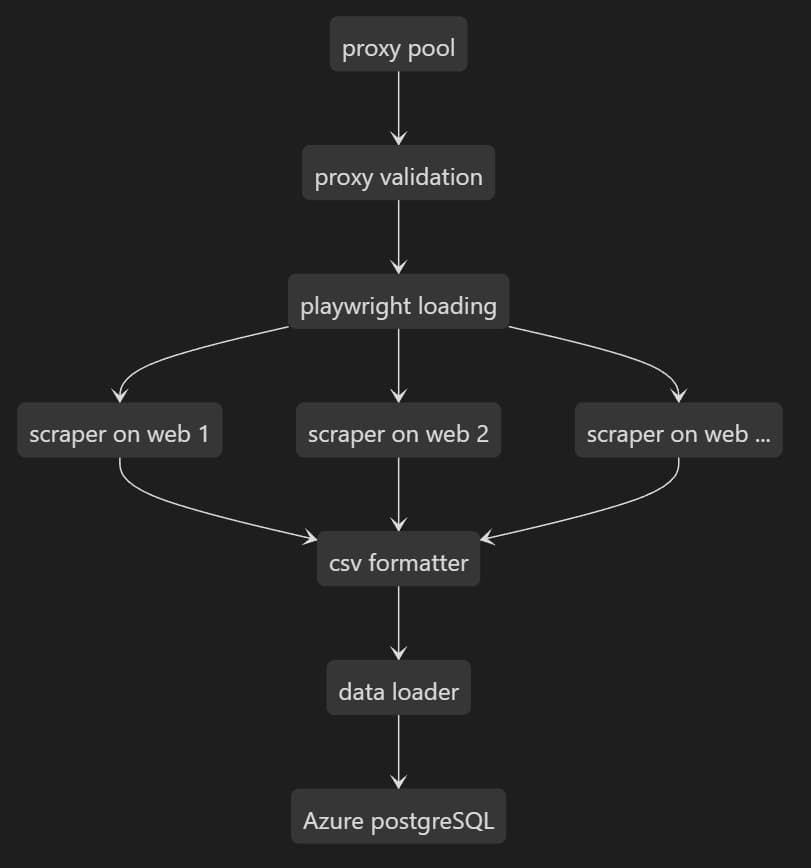
To have a large number of web scrapers collecting overlapping rent data is probably a good idea, given that all web scrapers are prone to changes made by the websites. It makes sense for me to go for diversity to make the data pipeline more robust. The data-lake can get at least a good coverage even if some scrapers fail. Noted here although data overlapping is a certainty in this way, it has its own value. Tracing a unit being put into the rental market and taken down throughout can be helpful for data analysis later on, the time-frame can play a role in the data modelling.
To manage a number of headless scrapers, some abstraction is needed. This is the playwright manager class and context manager I used:
import os
class BrowserManager:
def __init__(self, proxies_file="valid_proxies.txt", headers_file="user_agents.txt") -> None:
base_dir = os.path.dirname(os.path.abspath(__file__))
self.proxies = self.load_list(os.path.join(base_dir, proxies_file))
self.headers = self.load_list(os.path.join(base_dir, headers_file))
@staticmethod
def load_list(filename:str)->list:
with open(filename,'r') as f:
lines = [line.strip() for line in f.readlines() if line.strip()]
return lines
@staticmethod
def get_random_element(elements:list)->str:
from random import choice
return choice(elements)
def get_random_headers(self)->str:
return self.get_random_element(self.headers)
def get_random_proxy(self)->str:
return self.get_random_element(self.proxies)from contextlib import asynccontextmanager
import logging
from playwright.async_api import async_playwright
from util.browser_manager import BrowserManager
logging.basicConfig(level=logging.INFO)
@asynccontextmanager
async def browser_context(headless=False, proxy_enabled=False):
async with async_playwright() as p:
manager = BrowserManager()
header = manager.get_random_headers()
proxy = manager.get_random_proxy() if proxy_enabled else None
launch_options = {"headless": headless}
if proxy:
launch_options["proxy"]={"server":f"https://{proxy}"}
browser = await p.chromium.launch(**launch_options)
default_settings = {"extra_http_headers": {"User-Agent": header}}
if proxy:
default_settings["proxy"] = {"server": f"http://{proxy}"}
if proxy_enabled:
logging.info(f"browser with proxy {proxy}")
else:
logging.info("browser without proxy")
try:
yield (browser, default_settings)
finally:
await browser.close()browser_context can then be used inside your web scraper code as async functions, with options to switch off headless mode and use proxies. (A better approach here is actually to retry the scraper every time a proxy fails, but it brought more complexity than actually needed in my case). I have two text files in the same directory to store header and proxy information.
If you choose to use free online resources for proxy IPs like me, a validation program is probably a good idea, otherwise your scrapers would have a lot of timeout 30000 exceptions.
Task Management by Airflow
Airflow is used to manage all tasks ( Airflow Dags ) for all data stages in our project.
Comparing to simple cron jobs on Linux, Airflow offers several advantages in our case:
- web scraping, data loading, aftermath clean up, data cleaning, ETL etc can be done in a controlled sequence
- failed tasks in a sequence can be easily identified to rerun or abort ( important as web scraping is fragile as mentioned above )
- independent docker instances for scheduler, dags, web servers to reduce coupling in the system
- more flexible schedule management on when and how often scraping is needed
- web scraping using headless browsers requires a lot of memory and needs to manage the concurrent issue carefully. Here I used linear dependency rather than grouping for crawler tasks to manage the RAM consumption.
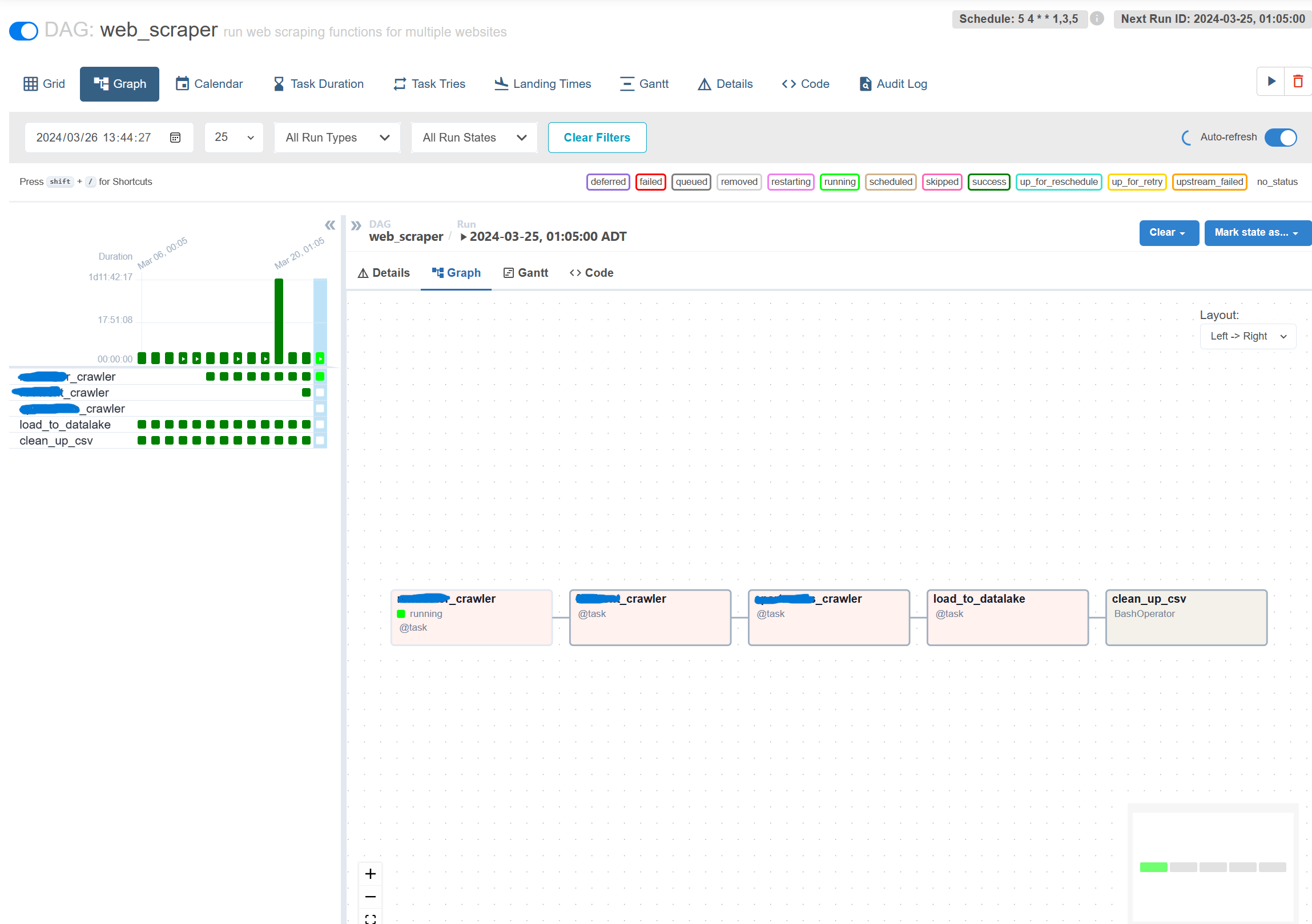 _Airflow web interface to manage our scraping and ETL tasks_
_Airflow web interface to manage our scraping and ETL tasks_
A more direct benefit of using Airflow is to run web scraping tasks in different containers ( Airflow workers )to run the tasks independently. Although for simplicity reasons I didn’t implement distributed scrapers, the system is set up in a way that makes it easy to introduce distributed workers for larger scale scraping
An example of web scraping dag used in Airflow:
dag_args = {
'owner':'julius',
'retries':5,
'retry_delay':timedelta(minutes=2)
}
with DAG(
default_args = dag_args,
dag_id='web_scraper',
description='run web scraping functions for multiple websites',
start_date=datetime(2024,3,4),
schedule_interval='5 4 * * 1,3,5'
) as dag:
sample_task1 = sample1_crawler()
sample_task2 = sample2_crawler()
sample_task3 = sample3_crawler()
load_to_datalake = load_to_datalake()
clean_up_csv = BashOperator(
task_id = "clean_up_csv",
bash_command='rm -f /opt/airflow/data/rent_data.csv'
)
sample_task1>>sample_task2>>sample_task3>>load_to_datalake>>clean_up_csva dag example
logging for debugging and detailed monitoring
Challenges of integrating Airflow with Playwright
Airflow with
Playwrightset up is not straightforward
How to set up Airflow with Playwright in a docker can be a challenge.
Apparently there is no ready image to use so self-built docker image is needed.
Airflow’s official image can be used as a base to install Playwright in docker-compose file. However, a simple
RUN python -m pip install pytest-playwright
RUN python -m playwright installwould run into problems as the official Airflow docker image lacks some dependencies to even install Playwright. Another way might be using Playwright’s official docker image and building from there to install Airflow. Or you can use Airflow source code directly. But they are also far from straightforward.
I’m sure there are better ways, but a feasible solution turned out to be to go into the docker instance ( in our case Airflow scheduler instance, it might depend on how you set up the Airflow distributed instances) and install Playwright using a command like this:
docker exec -it -u airflow af-test-airflow-scheduler-1 /bin/bash
Then as expected you can find the error messages stating that a large number of dependency packages were missing, then ran installation on those dependencies ( not an easy task as the dependency names are not always the package names, a manual search for the right packages and versions was needed. And no ChatGPT didn’t offer much help). The process had to be repeated 7~9 times as all the error messages could not show all missing dependencies as there were always recursive issues.
Once done, the built ready docker image is saved for deployment. Apart from Playwright, you might also need to install Python or other libraries in the docker if needed.
Web scraping is time-consuming and delicate
Since web scraping scripts are almost always specific to particular websites, they require some effort to get done. The problem of scraping data for Halifax region is that the data is not concentrated on one website, but rather scattered around. The cost-effectiveness is really low. What is more, web scraping is particularly vulnerable to even as small frontend or backend changes. Even if the DOM tree structure or API endpoints have only tiny changes, the scraper may still break down.
To overcome this, as I mentioned, multiple sites with a lot of overlapping data were scraped. Nearly all scrapers are written with async methods and multi-threading to enhance the speed.
Deploying data scrapers under Airflow on Cloud is not cheap
For simple data scraping schedules, deploying it on the cloud services is not cheap, local deployment can offer more computing power and memory with relatively low costs. A 16GB RAM mini PC can certainly do the job.